Duplicate content - czym jest i jak ją zidentyfikować? Jak radzić sobie z duplikatami na stronie?
(14 min czytania)

Czym jest duplicate content?
Duplicate content to zjawisko powielania treści, które ma miejsce, kiedy ten sam lub bardzo podobny tekst pojawia się w więcej niż jednym miejscu w Internecie. Może to wynikać z bezpośredniego kopiowania treści z jednej strony i wklejania jej na inną, lub z błędów technicznych witryny. Duplikacja może wystąpić również wtedy, kiedy w obrębie naszej domeny znajdują się bardzo podobne treści lub tekst skopiowany z innej witryny został zmieniony w bardzo niewielkim stopniu.
Google preferuje oryginalne treści, jednak zjawisko duplicate content nie jest bezpośrednio penalizowane przez wyszukiwarkę. Mimo to duplikacja treści może mieć negatywne skutki dla strony, wpływając na jej pozycjonowanie, widoczność oraz doświadczenie użytkowników. Gdy te same treści znajdują się w kilku miejscach w sieci, wyszukiwarka zazwyczaj wyświetla tylko jedną z nich w wynikach wyszukiwania. John Mueller, pracownik Google, wyjaśnia to w następujący sposób:
Jeśli masz tę samą treść na wielu stronach, nie pokażemy wszystkich tych stron. Spróbujemy wybrać jedną z nich i ją pokazać. Nie jest z tym związany żaden negatywny sygnał. W wielu przypadkach to normalne, że niektóre treści są udostępniane na różnych stronach.
Tłumaczenie własne
W praktyce oznacza to, że strony z powieloną treścią mogą nie być widoczne dla użytkowników, co ogranicza ich zasięg i potencjalny ruch.
A co w przypadku publikacji tej samej treści w różnych formatach? Przykładowo, kiedy artykuł blogowy zostanie przekształcony w film na YouTube.
Na szczęście, użycie tej samej treści w różnych mediach nie jest traktowane jako duplikacja. Podobnie, elementy powtarzające się na wielu stronach, takie jak stopki, nagłówki, menu nawigacyjne czy inne fragmenty strony, które logicznie pojawiają się na wielu podstronach witryny, nie są uznawane za duplikację treści.
Skutki duplikacji treści
Tak jak wspomnieliśmy, duplicate content, może negatywnie wpłynąć na pozycjonowanie strony. Po pierwsze, wyszukiwarki internetowe mogą wybrać inną stronę, niż tę, którą chcemy wyświetlać w wynikach wyszukiwania na określone zapytanie. W konsekwencji użytkownicy mogą nie trafić na treść, którą chcemy im pokazać.
Po drugie, wyszukiwarki mają ograniczone zasoby do indeksowania stron internetowych. Duplikaty marnują crawl budget, ponieważ zmuszają roboty do indeksowania niepotrzebnych wersji, co spowalnia proces znajdowania nowych treści. Zamiast indeksować nowe i zaktualizowane strony, wyszukiwarki mają więcej niepotrzebnych stron do zaindeksowania, co spowalnia proces pojawiania się świeżych treści w wynikach wyszukiwania.
Zduplikowane treści osłabiają również ogólną siłę SEO strony, kiedy backlinki kierują do obu wersji www i wzmacniają profil linków nie tej strony, którą chcemy pozycjonować.
Rodzaje duplicate content
Zduplikowana treść dzieli się na dwa główne rodzaje.
Wewnętrznie zduplikowana treść dotyczy sytuacji, w której ta sama treść pojawia się na wielu stronach w obrębie jednej witryny. W tej sytuacji wyszukiwarki mogą mieć trudność z określeniem, którą stronę zaindeksować lub jak ją ocenić. Zewnętrzna duplikacja odnosi się do sytuacji, w której ta sama treść pojawia się na różnych witrynach. Tego rodzaju duplikacja może wpłynąć na autorytet i wiarygodność witryny, ponieważ wyszukiwarki będą miały trudności z ustaleniem oryginalnego źródła treści lub z priorytetyzacją stron. Przyjrzyjmy się bliżej, co może być przyczyną duplikatów i na co należy zwrócić uwagę, aby uniknąć problemów.
Wariacje adresów URL
Duplikacja treści wynikająca z wariacji URL jest powszechnym problemem w zarządzaniu stronami internetowymi. To sytuacja, w której różne wersje adresów URL prowadzą do tej samej treści. Zjawisko może występować z kilku powodów, w tym wykorzystania parametrów śledzenia, różnic w protokołach oraz struktury adresów URL.
1. Parametry śledzenia
Parametry śledzenia, takie jak parametry UTM czy kody Pixela Facebooka, są używane do monitorowania efektywności kampanii marketingowych. Nieprawidłowe użycie tych parametrów może jednak prowadzić do powielania treści. Na przykład różne kolejności parametrów (np. zamiana miejscami nazwy kampanii i źródła) mogą skutkować traktowaniem przez wyszukiwarki tych adresów jako oddzielnych stron, mimo że prowadzą do tej samej treści.
2. Różnice w protokołach (HTTP vs. HTTPS)
Posiadanie strony dostępnej zarówno przez HTTP, jak i HTTPS prowadzi do duplikacji treści. HTTP przesyła dane bez szyfrowania, podczas gdy HTTPS zapewnia bezpieczne połączenie. Wyszukiwarki mogą indeksować obie wersje jako oddzielne strony, jeśli certyfikat SSL nie zostanie poprawnie wdrożony.
3. Prefiks www oraz ukośnik na końcu adresu URL
Podobnie jak w przypadku różnic w protokołach, strony zarówno z prefiksem www, jak i bez niego, mogą być traktowane jako oddzielne strony. To samo dotyczy ukośnika (/
4. Automatycznie generowane struktury URL
Niektóre systemy CMS mogą automatycznie generować różne adresy URL dla tej samej treści, zawierające dodatkowe informacje, takie jak nazwa i kategoria produktu. Taka sytuacja może wystąpić wtedy, kiedy przypisujemy produkt do kilku kategorii, a każda z nich wyświetli inny adres URL do tej samej strony.
Przykładowo, do Produktu 123 można przejść zarówno ze strony kategorii Suplementy, jak i Oleje, co odzwierciedlają poniższe adresy URL:
www.moj-zwierzak/suplementy/ produkt-123 www.moj-zwierzak/ oleje/ produkt-123
Kluczowe jest wówczas stosowanie kanonicznych adresów URL, które wskażą wyszukiwarkom preferowaną wersję strony do zaindeksowania.
5. Paginacja
Paginacja to podział treści na mniejsze części i umieszczenie ich na osobnych stronach. Jest powszechnie stosowana w e-commerce, zwłaszcza w katalogach produktów, ponieważ pozwala na szybszą indeksację. Jednak kolejne strony mogą mieć bardzo podobne lub te same meta znaczniki lub opisy, co sprawia, że wyszukiwarki mogą traktować je jako duplikaty.
Może również wystąpić sytuacja, w której ta sama strona będzie dostępna z parametrem strony (page) i bez niego. Widać to na poniższym przykładzie - adres URL sklep.pokusa.org/


Przeczytaj nasz artykuł, aby dowiedzieć się jak odpowiednio wdrożyć paginację na swojej stronie!
6. Nieprzemyślane stosowanie tagów i kategorii
Nieodpowiednie używanie tagów może prowadzić do duplikacji treści na stronach internetowych na kilka sposobów. Częstym przykładem jest tworzenie niemal identycznych stron kategorii i tagów, które dotyczą tożsamych tematów i grupują niemal identyczną treść.
Tworzenie tagów i kategorii tylko z jednym wpisem będzie również prowadziło do duplikacji. Dodawanie nowych podstron, które zawierają lub kierującą do tej samej treści powoduje konkurencję pomiędzy naszymi stronami.
Skopiowana treść
Kopiowanie tekstów lub materiałów z innych stron internetowych, a nawet z własnej witryny przyczynia się do duplikacji treści. Jest to jedna z praktyk, która może prowadzić do problemów dla oryginalnego źródła, ale także dla strony, która odtworzyła treść.
Powielanie może dotyczyć nie tylko całej treści, ale także cytowania zbyt dużych fragmentów tekstu. W drugim przypadku należy upewnić się, że strona umożliwia korzystanie z jej treści. Przy cytowaniu kluczowe jest, aby zawsze podawać źródło, ale przede wszystkim starać się w miarę możliwości pisać unikalne treści i dodawać własne spostrzeżenia.
Może się zdarzyć sytuacja, w której zauważysz, że ktoś skopiował twoją treść. Jest to szczególnie problematyczne, jeśli twoja witryna internetowa ma niższy autorytet domeny. Wówczas skopiowana treść może wyprzedzić oryginalną wersję w wynikach wyszukiwania. Co należy zrobić w tej sytuacji? W pierwszej kolejności zaleca się skontaktowanie z właścicielem witryny i zażądanie usunięcia lub modyfikacji treści.
Jeśli to rozwiązanie nie będzie skutecznie, takie sytuacje można zgłaszać za pomocą formularza udostępnionego przez Google. W przypadku kiedy zgłoszenie zostanie uznane za zasadne, strona zniknie z wyników wyszukiwania.
Opisy produktów w e-commerce
Częstym źródłem duplikatów są opisy produktów oferowanych przez wiele sklepów internetowych. Jeśli sklepy kopiują opisy od producenta lub od siebie nawzajem, to zachodzi zjawisko duplikacji treści.
W przypadku opisów produktów duplikacja może mieć nie tylko charakter zewnętrzny, ale też wewnętrzny, kiedy dla każdego parametru jakiegoś produktu (np. kolor, rozmiar) tworzymy nowe wersje strony. Jeśli zależy nam na tym, aby każdy rodzaj produktu znajdował się na osobnym adresie URL, musimy zadbać o unikalne opisy.
Różne wersje językowe strony
Kolejnym problemem, z którym możesz się spotkać, są duplikaty treści na stronach międzynarodowych. W przypadku witryn posiadających wersje dostosowane do różnych krajów lub języków, istnieje tendencja do tworzenia podobnej lub identycznej treści, a wyszukiwarki mogą ją interpretować jako duplikat. To z kolei utrudnia im ustalenie, który wariant pokazać użytkownikom. Ryzyko jest mniejsze, kiedy zakres oferowanych produktów i usług różni się w zależności od regionu lub kraju. Jednak w przypadkach, kiedy firmy oferują ten sam asortyment w różnych językach, może to skutkować konkurencją między stronami o podobnej treści.
Aby uporać się z problemem duplikowania treści na stronach w różnych językach, należy tworzyć unikalne, odpowiednie treści dla każdego rynku treści i unikać tłumaczeń maszynowych. Ponadto, użycie prawidłowego atrybutu hreflang jest kluczowe, ponieważ pomaga wyszukiwarkom w identyfikacji i wyświetlaniu odpowiedniej wersji strony dla użytkowników z różnych regionów.
Jak zidentyfikować duplikaty?
Jednym z najszybszych (ale nie obejmujących całą witrynę) sposobów sprawdzenia, czy nie ma zduplikowanej treści, jest skopiowanie około dziesięciu słów tekstu ze swojej witryny, a następnie wklejenie go w cudzysłowie do wyszukiwarki Google. Jest to najbardziej podstawowy sposób weryfikacji duplicate content.
Ta ręczna metoda, którą można wielokrotnie stosować do szerokiego zakresu stron i treści, jest jednak czasochłonna i nie zapewnia pełnego rozwiązania w przypadku złożonych serwisów internetowych. Szczególnie w przypadku większych, bardziej dynamicznych witryn, w których treść stale się rozwija i zmienia, technika ta jest niepraktyczna. W takich przypadkach warto polegać na dodatkowych platformach, aby skuteczniej rozpoznawać duplikaty treści.
Narzędzia SEO takie jak Siteliner, Screaming Frog, czy Google Search Console pozwolą nam przeprowadzić bardziej kompleksową analizę.
Google Search Console (GSC)
Serach Console to bezpłatne narzędzie od Google, które pomaga monitorować widoczność strony i identyfikować różne błędy. W sekcji Indeksowanie, w zakładce Strony, możemy znaleźć następujące komunikaty GSC, które mogą oznaczać problemy z podobną treścią:
- Duplikat, użytkownik nie oznaczył strony kanonicznej - Google znalazł duplikat strony, ale użytkownik nie określił adresu kanonicznego. Klikając komunikat, przeanalizujemy wskazane strony, a wybierając konkretny URL, zobaczymy adres kanoniczny wybrany przez Google.
- Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik - chociaż określiliśmy adres kanoniczny, Google zdecydował się wybrać inny URL. Należy dokładnie przeanalizować strony, które wskazała wyszukiwarka, a następnie zmodyfikować wersje kanonicze.
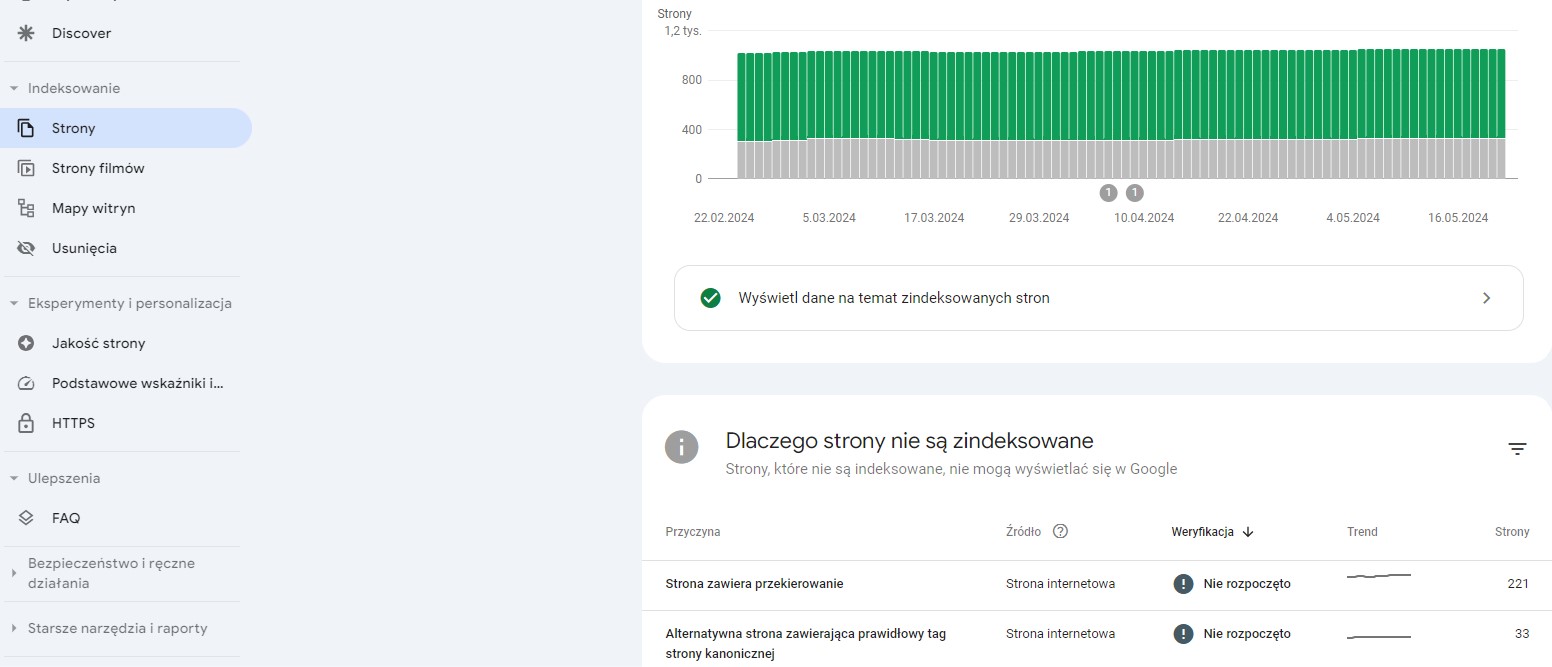
Komunikat Alternatywna strona zawierająca prawidłowy tag strony kanonicznej oznacza, że Google zrozumiał, która wersja strony jest kanoniczna, i odpowiednio zaindeksował treść. Jest to sygnał, że tagi kanoniczne są prawidłowo używane na stronie.
Siteliner
Siteliner to kompleksowe narzędzie, które bada strukturę witryny, wykrywa uszkodzone linki, osierocone strony i identyfikuje zduplikowaną treść w obrębie serwisu. Raport dostarcza informacji o procentowej zawartości duplikatów, stronach, na których znajduje się powielona treść oraz sugeruje sposoby poprawy.
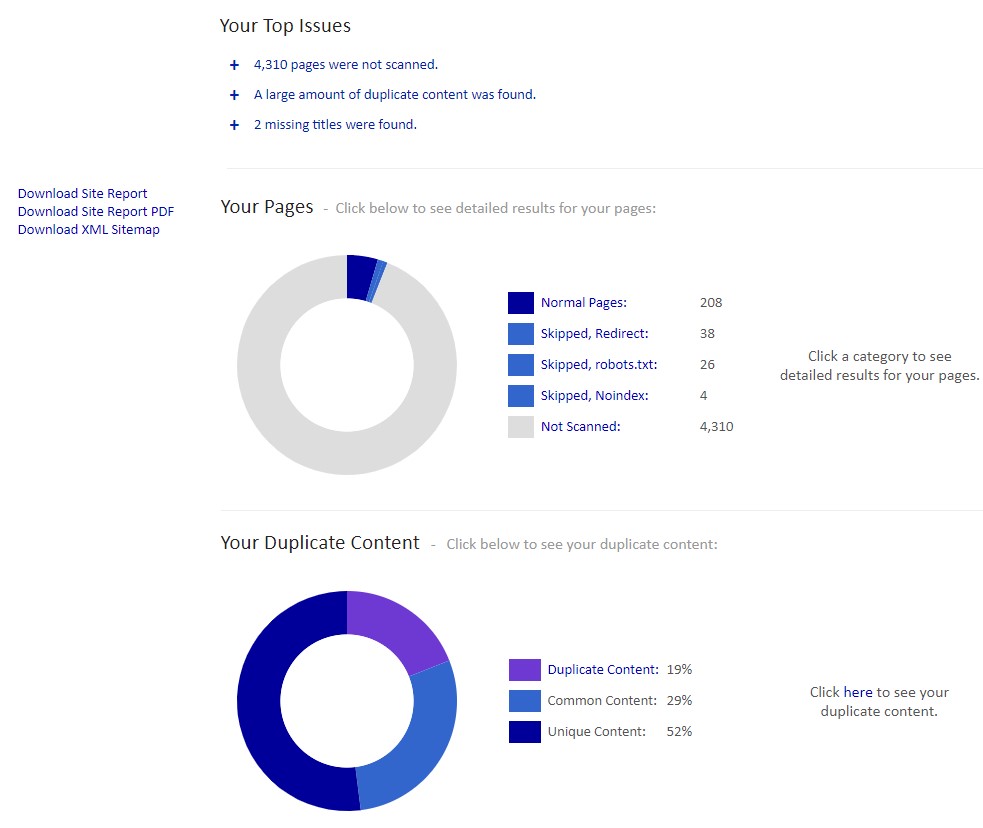
W raporcie zobaczymy konkretne adresy URL, które zostały oznaczone jako duplikaty, szczegóły dotyczące liczby zduplikowanych słów, procent zgodności oraz strony, na których została znaleziona ta sama treść. Wybierając konkretny link, Siteliner podświetli treść znalezioną na kilku stronach witryny oraz liczbę powtarzających się słów.
Darmowa wersja narzędzia Siteliner umożliwia użytkownikom przeskanowanie do 250 stron, co sprawdzi się w przypadku niewielkich stron internetowych i blogów.
Screaming Frog
Screaming Frog to narzędzie, które analizuje witryny internetowe. W trakcie crawlowania, oprogramowanie identyfikuje dokładne duplikaty treści. Darmowa wersja umożliwia przeanalizowanie 500 adresów URL.
Aby rozszerzyć audyt o treści bardzo podobne, należy w ustawieniach włączyć opcję Duplikaty częściowe w ustawieniach w górnym menu: Konfiguracja > Treść > Duplikaty. Domyślny próg podobieństwa wynosi 90%, ale można go zmienić, a także wykluczyć strony wyłączone z indeksu.
Zidentyfikowane strony o dużej zawartości duplikatów należy następnie przejrzeć ręcznie.
Copyscape
To narzędzie umożliwia analizę konkretnej podstrony pod kątem zewnętrznej duplikacji treści. Po wpisaniu adresu URL, narzędzie generuje raport, w którym znajdują się strony zawierające identyczną treść.
Niestety, darmowa wersja tego narzędzia posiada pewne ograniczenia. Pozwala ona na wykonanie jedynie kilkunastu wyszukań tygodniowo.
Jeśli potrzebujesz przeprowadzić więcej analiz lub posiadasz większą stronę internetową, zaleca się skorzystanie z płatnej wersji, która oferuje nielimitowaną liczbę wyszukiwań oraz dodatkowe funkcje, takie jak:
- Skanowanie całej domeny: Możliwość przeanalizowania wszystkich podstron serwisu www pod kątem duplikacji treści.
- Raporty szczegółowe: Szczegółowe informacje o znalezionych duplikatach, w tym procentowe porównanie treści.
Jak radzić sobie z duplikacją treści na stronie?
Wiemy już, że duplikacja treści może negatywnie wpływać na pozycjonowanie strony. Istnieje kilka metod, których celem jest wskazanie Google, która treść jest preferowana, czyli oryginalna. Przeprowadzaj regularne audyty SEO, aby wykryć wszelkie formy duplikacji i jak najszybciej podjąć działania naprawcze.
Przekierowania 301
Przekierowanie 301 to trwała metoda automatycznego przekierowywania odwiedzających na inny adres URL, pozwalająca uniknąć powielania treści. Technika ta pozwala wyeliminować konkurencję pomiędzy podstronami o tej samej treści, ponieważ wszystkie linki będą prowadzić do tej samej strony. Dzięki temu oryginalny adres URL otrzymuje największą siłę linkowania, co może znacząco poprawić ranking witryny w wynikach wyszukiwania Google.
W przeciwieństwie do przekierowania 301, przekierowanie 302 jest rozwiązaniem tymczasowym i nie rozwiązuje problemu duplikacji treści długoterminowo. Głównym celem przekierowań 302 jest poprawa komfortu użytkownika w przypadku tymczasowych zmian treści, a nie informowanie wyszukiwarek o trwałych zmianach adresu. Dlatego przekierowanie 301 jest właściwym wyborem w przypadku zduplikowanych treści, ponieważ wskazuje na trwałe przekierowanie, pomagając w ten sposób potwierdzić oryginalną treść i zapewnić jej prawidłowe indeksowanie w wyszukiwarkach.
Znacznik rel="canonical".
Bardzo ważnym narzędziem jest tag rel="canonical". Znacznik umieszczany jest w sekcji <head> kodu HTML witryny i informuje wyszukiwarki, że dana strona jest kopią innego preferowanego adresu URL.
Używaj canonicali, gdy masz kilka stron o podobnej lub identycznej treści, ale chcesz, aby roboty indeksowały tylko jedną z nich. Dzięki temu znacznikowi wyszukiwarki dają pierwszeństwo tak oznaczonej stronie podczas indeksowania i rankingu, natomiast inne strony ze zduplikowaną treścią są traktowane jako podrzędne lub pomijane w wynikach wyszukiwania.
Znacznik noindex
Tag noindex instruuje roboty wyszukiwarek, aby nie indeksowały określonej strony internetowej. Kiedy ten tag zostanie zaimplementowany w kodzie strony, informujesz wyszukiwarkę, aby nie oceniała takiej strony i wykluczyła ją z wyników wyszukiwania.
Kiedy warto używać tego znacznika? Tag noindex jest używany w przypadku stron w fazie produkcji, stron ze zduplikowaną treścią lub stron zawierających poufne informacje. Przykładowo, jeżeli w kampaniach sezonowych potrzebny jest dodatkowy landing page, który będzie lepiej konwertował ruch, to tagiem “noindex” można oznaczyć stronę docelową kampanii PPC.
Znacznik noindex warto też stosować w przypadku filtrów w e-commerce, które nie dodają żadnej nowej wartości - przykładem może być sortowanie według ceny lub popularności. Takie strony nie powinny być indeksowane, ponieważ duplikują one treść strony głównej kategorii. Filtry, które znacząco rozszerzają kategorie produktów i pomagają sprecyzować wyszukiwanie, powinny być indeksowane.
Pamiętaj - nie używaj tagu noindex i canonicali jednocześnie na tej samej stronie. Może to spowodować problemy z indeksowaniem strony przez wyszukiwarki.
Unikalne treści
Nie zapominaj, jak ważne jest tworzenie unikalnych treści. Zainwestuj czas i zasoby potrzebne na stworzenie unikalnych, wartościowych i odpowiednich treści dla odbiorców. W ten sposób poprawisz nie tylko SEO, ale także doświadczenie użytkownika. Stosuj różne techniki różnicowania treści - rozszerzaj wątki, używaj synonimów i pokrewnych terminów, opisz temat z innej perspektywy.
Narzędzia lub wtyczki, które automatycznie generują tekst, choć pomocne, mogą prowadzić do niezamierzonego powielania treści. A skoro mowa o generatorach tekstu, sprawdź nasz artykuł, w którym przyglądamy się, jak detektory radzą sobie z wykrywaniem treści AI!
Jednocześnie upewnij się, że cały zespół jest świadomy znaczenia unikania duplikatów treści i znaczenia oryginalnych treści. Skup się na strategiach, które pozwalają tworzyć oryginalne treści oparte na badaniach. Stosując dobre praktyki, będziesz w stanie poprawić wydajność swojej witryny i zwiększyć swoją obecność w wyszukiwarkach.

International SEO Specialist


