(1 хвилин читання)

Що таке LLM або великі лінгвістичні моделі
LLM — це машинні моделі, які аналізують і генерують контент, засновані на великих наборах даних. Найвідомішими на сьогодні є GPT, PaLM, BERT, LaMDA, LLama. До речі, всі вони трансформери. При цьому масштаб таких моделей вражає - вони тренуються на даних об'ємом у петабайти і містять мільярди параметрів.
Наприклад, модель PaLM від Google має 540 мільярдів параметрів і використовує нову архітектуру Pathways для ефективного навчання. PaLM2 — трохи менше — 340 мільярдів. Завдяки цьому PaLM може вирішувати широке коло завдань: переклад, класифікація текстів, відповіді на запитання тощо.
LLM спочатку тренуються вирішувати загальні задачі обробки природної мови. А потім їх можна адаптувати до конкретних сфер, наприклад медицини, за допомогою невеликих наборів даних.
Пошук використовує їх, щоб розуміти контекст, класифікувати контент, розуміти значення слів. Наприклад, коли користувач вводить запит в пошук, в деяких випадках Google може задіяти BERT, щоб зрозуміти, що користувач має на увазі і чого хоче. А зараз вже і TW-BERT.
Про граф знань Google
Граф знань Google — це розширена база даних, що агрегує інформацію про різні сутності і їх взаємозв'язки і характеристики. Сутностями можуть бути дуже конкретні об’єкти, такі як люди, компанії, товари, а також події, місця і абстрактні поняття, концепції, факти. Це така спроба оцифрувати всесвіт. З особливою увагою Google ставиться до іменних сутностей — це імена і назви конкретних людей, компаній, подій і т.і. Приклад іменної сутності компанії — Whitepress.
На відміну від звичайних баз даних сутності пов'язані між собою відношеннями. Це ребра, які з'єднують вузли і описують, як одна сутність відноситься до іншої.
Дві сутності, пов'язані між собою, називаються триплетом: суб'єкт - предикат - об'єкт. Наприклад, Олеся пише статтю. Олеся Коробка — іменованна сутність суб’єкт, стаття — просто сутність об’єкт, а пише — зв'язок поміж ними або предикат.
Олеся -> пише -> стаття
суб'єкт -> предикат -> об'єкт
Також в граф додаються мітки — це додаткові характеристики, які допомагають класифікувати сутності.
Google застосовує граф знань для формування панелей знань і фактологічних відповідей на питання користувача. Коли в запиті присутня конкретна сутність і Google може її виділити, то він додає спеціальні блоки, які необов’язково відповідають на запит, але можуть надати додаткову інформацію.
Джерела даних для графа знань і лінгвістичних моделей
Основними джерелами даних для графа знань Google є Вікідані, Вікіпедія, відкриті дані державних установ, комерційних компаній, трастові публічні бази даних. Дані можуть бути структурованими, напівструктурованими (таблиці, списки на сайтах) та неструктурованими (звичайний текст).
Про джерела даних до лінгвістичних моделей точних даних немає. Відомо, що Google використовував датасети новинних сайтів, корпус книг, можливо, очищені дані Common Crawl і багато іншого, в тому числі медичні датасети.
Чому потрібні обидві технології і чи можна залишити тільки одну
Лінгвістичні моделі фокусуються на векторному просторі. Для Google при використанні векторів важливо зрозуміти саме значення слова або фрази. Тому важлива мова слова, контекст, які ще інші слова його оточують, наскільки статистично часто вони всі разом трапляються в одному документі. Фактологічна достовірність при цьому не важлива.
В графі знань навпаки. Акуратність дуже важлива. Траст, довіра, достовірність — це все відноситься до сутностей в графі знань. Значення слова сутності не має значення. Сутність все одно перекладається в мову нуль і їй надається певне місце в базі даних. Сутність універсальна в цьому сенсі. Для Google важливо розрізняти сутності поміж собою і не плутати їх.
Оптимізація сайту під граф знань
Щоб дані про ваш бізнес або сайт ефективно використовувались в графі знань, потрібно:
- Використовувати зрозумілий для екстракторів шаблон. Краще, коли він однаковий для сторінок одного типу, структурований. Структурувати інформацію можна за допомогою таблиць, списків, розмітки, ієрархії заголовків.
- Наповнювати сторінку повними та достовірними даними, вказувати всі необхідні атрибути або характеристики сутності.
- Використовувати семантичне маркування із зазначенням сутностей і зв'язків між ними.
- Оптимізувати контент під відповідні сутності, не мішати все в кучу, а також впевнитись, що ви з Google однаково розумієте, про яку сутність йдеться мова і що він саме так її і екстрактує.
- Впевнитись, що є внутрішні і зовнішні посилання, які в анкорі або заголовку сторінки мають необхідну сутність, яку коректно екстрактує бот.
Таким чином можна отримати інфоблок в пошуку, панель знань про компанію чи сайт, а також покращити позиції за рахунок того, що Google буде краще розуміти контент.
Як видно, граф знань відкриває нові можливості для пошукової оптимізації. Головне - максимально структурувати дані на сайті і наповнити його корисним та достовірним контентом.
Вплив графа знань на ранжування
Чи впливає граф знань на позиції сайту в пошуку? Якісне структурування даних полегшує їх обробку Google.
Також наявність сайту чи його сторінок у відповідях Google, інфоблоках, інших функціях пошуку підвищує ймовірність кліків на нього з пошуку і видимість взагалі.
Вплив трансформерів на ранжування

Це іноді звучить дивно для SEOшників, але оптимізувати під BERT і інші трансформери неможливо. Наприклад, BERT Google використовує для того, щоб краще розуміти намір і контекст запиту користувача. Він сам по собі вимагає дуже багато ресурсів. Достеменно невідомо, чи використовує його Google навіть для всіх запитів, не кажучи вже про вебсторінки. Спробуйте ось самі. Написала вам код, щоб ви могли просто створити BERT’ом ембедінги ключових слів.
Ембедінги в пошуку
Основою семантичного пошуку Google становлять ембедінги, а точніше порівняння їх відповідної подібності. Ембедінги — векторні представлення, які кодують семантичну інформацію про контент. Так Google може не тільки розуміти запити користувачів, але і повертати відповідні результати пошуку.
Ось, як це працює:
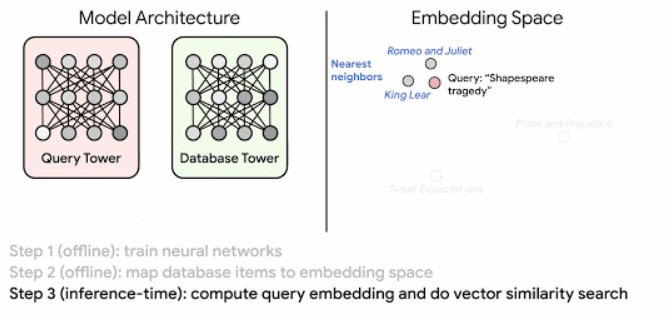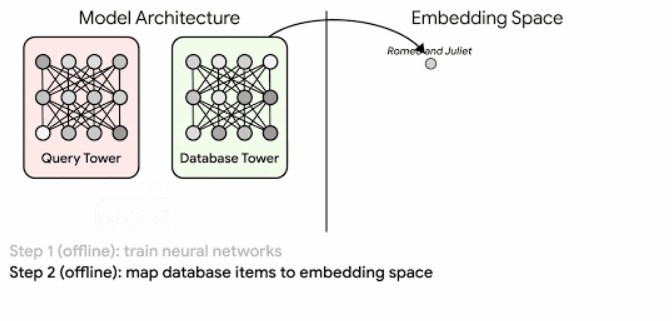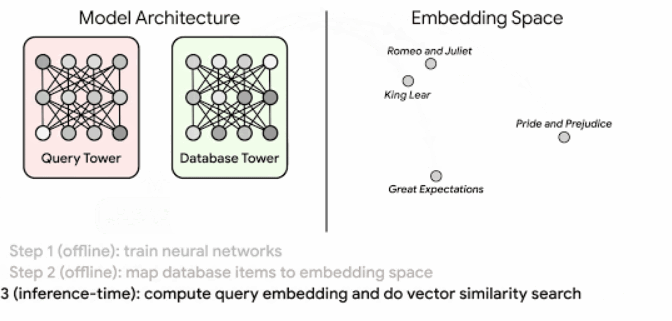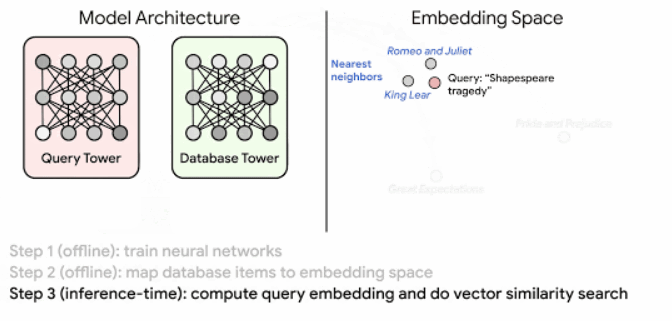
Про алгоритм ScaNN, який використовує Google, детальніше можна прочитати тут.
Як використовувати ембедінги і LLM в SEO
Насправді можна робити дуже круті штуки, але ось тільки декілька прикладів:
- Створювати якісний, інформативний контент, що передає повне семантичне значення тем, а не лише ключові слова. Це дозволяє пошуковикам точніше представляти сторінки за допомогою ембедінгів.
- Створити свій датасет і зафайнтьюнити обрану модель під себе, щоб генерувати різний контент.
- Аналізувати проекції ембедінгів, щоб виявити прогалини в контенті та можливості.
- Використовувати вектори слів та інструменти ембедінгів для розширення ключових слів семантично пов'язаними термінами.
- Кластеризувати, класифікувати, розмічати контент на сайті.
- Генерувати контент, будь-який. Наприклад, для відповідей на поширені питання користувачей.
- Автоматично анотувати контент, наприклад, після генерації опису товара.
- Розробити рекомендаційні системи, засновані на подібності векторів користувачів і товарів.
До чого тут блокчейн та верифікація даних
Технологія блокчейну теоретично може допомогти верифікувати дані, які потрапляють у граф знань Google або в будь-яку іншу базу знань на векторах. Блокчейн забезпечує незмінність та прозорість транзакцій.
Google може інтегруватися з децентралізованими реєстрами на блокчейні, щоб перевіряти достовірність даних про сутності. Це підвищить якість графа знань.
З іншого боку, розміщення структурованих даних про сайт чи компанію в блокчейні може слугувати їх верифікацією для Google.
Проти цього методу висловлюється Tim Berners Lee. Основними недоліками використання блокчейну для пошуку майбутнього при переході на web3.0 є:
- Повільність,
- Надмірна вартість,
- Публічність.
Ще подивимось, як це буде розвиватись.
Висновок
Отже, сучасні технології, такі як LLM, ембедінги та граф знань відкривають нові можливості для контент-маркетингу та SEO. Вони дозволяють створювати якісний, структурований і семантично змістовний контент, який краще сприймається пошуковими системами.
Щоб успішно застосовувати ці технології, потрібні знання та креативний підхід. Але ті, хто опанують LLM, ембедінги та граф знань отримають значну перевагу на ринку контент-маркетингу та SEO в найближчі роки.

SEO Entrepreneur


